Computer Programming Tutorials
In today's society computers and computer information systems are implemented
everywhere and are used to perform a diverse variety of functions and tasks.
The applications that computers can be put to use in are numerous and limited
only by the imagination. At the most basic level a computer is simply a
device which accepts information, processes it in a well defined,
deterministic fashion then spits the resulting information back out. The
general concept of a computer and what it does is very simple. However, the
conceptual simplicity of the computer makes it extremely versatile and
flexible as to what it can be implemented as and used for. This means
that a computer can be any device which accepts, processes and outputs
information and in doing so accomplishes some useful task. Computers come in
all sizes, shapes and forms. Besides being implemented as the familiar desktop
computer, a computer can be a server, mainframe, laptop device, palmtop
device, embedded system, micro controller, watch, cellular phone, calculator,
etc... But, no matter what form a computer takes they all share one thing in
common. The usefullness and reliability of a computer is dependent on the
quality of the software that is written for it to run. All computers need
software for them to perform their intended task and all good quality
software needs to be designed, written and maintained by competent and
skilled computer programmers.
The purpose of this section is to present a tutorial in computer science and
and modern programming techniques. Some of you who are viewing this section
may find some of this information obvious, especially if you are a veteran
programmer or analyst. Please keep in mind that some people may not find this
stuff obvious, especially for those with no previous programming experience.
However, if you are bored and wish to skip ahead to the demo section click
here.
Lets start off with a very brief overview of computer science and the art of
computer programming.
Computer Science is the study of algorithms and the machines that implement
them. Every program ever written first starts off as an algorithm. The algorithm
expresses a sequence of procedures that is used to solve a well
defined problem. Once an algorithm is established it is implemented in a
programming language usually this would be a high level language
which shares many similarities in terms of syntax and semantics to the way an
algorithm is expressed. Algorithms are basically ideas and these are usually
written out in plain simple language like English. Algorithms expressed in this
form is commonly called pseudo code. This is important because the most
critical and difficult part of a program is not the computer language code, but
the plan or idea that is used for carrying out the task. Once you come up with
the plan or idea it can be implemented it any language you wish to use (of course
choosing the language that has the features necessary to do the job always helps).
Coding the program is always the easy part. An effective algorithm will make the
difference in both the reliability and efficiency of a program.
What kind of task can a computer solve? The task must be well defined.
This implies the following 4 properties:
- Unambiguous - meaning is clear
- Deterministic - unique action specified
- Feasible - can be performed
- Finite - comes to an end
Structure of Algorithms
How is a complex algorithm built from simple actions?
- Form a sequence of simple steps (Add a number to another number)
- Repeat a simple action (Do this 1000 times)
- Make a choice between alternative actions (if number is greater than 100 then do... otherwise do...)
The "simple steps" being combined may be:
- Primitive Operations (plus, minus, store in variable, test if positive ...)
- Sub-Algorithms (these are built out of simpler steps)
Any algorithm however complex, can be built by combining primitive
operations and sub-algorithms in accordance with four formation rules:
- Sequencing (placing the steps in the order in which they should be executed)
- Repetition (the repeated execution of a step or a sequence of steps)
- Choice (a decision which resolves into the execution of a sequence of steps or an alternative sequence of steps)
- Sub-procedure (grouping a sequence of steps which may themselves have all of the above attributes into a single step)
Complexity of Algorithms
If we are writing a simple program that will do simple calculations of a small
set of data, then the efficiency of the program is of little importance. However,
if the computations are complex and therefore time-consuming then the time
efficiency of the algorithm may be critical to the success of the program
Since the quality of the code and the speed of execution of instruction is
system dependent, computer scientists have came up with a methodology for
calculating time efficiency which excludes those factors and is primarily based
on the input to the algorithm.
The time complexity of an algorithm is expressed in the form of a formula which
gives the general magnitude of the algorithm in terms of the average size of
computation needed run an algorithm to completion. Formulas shown in this way are
called Big-Oh notation, which has the form O(x) where a formula is substituted
in place of "x"
-
for example a block of simple instructions enclosed within a loop has a time
complexity O(n). The reason is that the sequence of code will be executed "n"
times within the loop where "n" is the limit of the loop. This is referred
to as linear time.
-
A nested for loop with the limits of each loop set to n will have time complexity
of O(n2). The reason is that the code will be executed "n" times by the inner
loop, but the inner loop will be executed by the outer loop "n" times as well
giving a generic formula of n x n or n2. This is referred
to as quadratic time.
What about formulas in which there are multiple terms of varying degrees?
For instance, lets take the real example of the common select sort algorithm:
// The following code is the select sort algorithm
// implemented in the C programming language
for (outer = 0; outer < limit - 1; ++outer)
for (inner = outer + 1; inner < limit; ++inner)
if (array[inner] < array[outer])
swap(array[inner], array[outer]);
if you multiply the limits of both loops you end up with a formula of:
limit2 - limit
The formula has two terms the first has a degree of 2 the other has a degree of 1
In this case you take the term with the highest degree and disregard all the
other terms.
The next section will go over some modern techniques in programming and
program design.
Programming and Program Design Techniques
Creating and Running Programs
Before I start with techniques I'll go over a very simplified process
for developing programs. This is essentially what all programmers do when given
a problem to solve. The information presented in the diagram is fairly obvious
and needs no further explanation.

Design Techniques
In designing any serious large scale program, technique is very important.
Technique often makes the difference in whether the resulting program becomes
an unmanageable, unreliable, nearly indecipherable monstrosity or an elegant,
easy to understand, easy to extend piece of software engineering.
To go over all the modern techniques available to the programmer/designer
would take far too much space. Instead I'll skim over briefly the general
concepts involved.
The most general, useful and straight forward technique for designing a program
is to use encapsulation and abstraction.
In program commands you specify some unique operation to be done on a piece of
data which changes its value in some way. The word to note here is data.
An unique operation is done to a piece of data for each command you specify against
it. However, not all operations on the piece of data is valid. This all depends
on what the data was intended to be used for.
For example:
suppose you intend to use a particular piece of data to hold the results of
a mathematical calculation then the type of the data would be numeric
such as a floating point value or an integer value as opposed to alphanumeric,
which would include letters as well as numbers. For example, this page is a
document with alphanumeric data, since it includes words that can have both
letters and numbers. But, not all operations that are valid for numbers are
valid for words and vice versa. For instance, all the basic arithmetic operations
add, subtract, multiply and divide is valid for numbers, but these don't have
any clearly defined meaning if we apply them to words. What does it mean to
multiply the words: "hello" and "world"? Similarly, we may come up with a few
operations that we find useful when applied to words such as joining two words
to make a new word (concatenation) or searching through a word and
replacing all occurrences of a particular letter with another letter, but again
these operations don't make sense or have any useful purpose when applied to
numbers. Sure when you join "456" with "789" you end up with a new number
"456789", but you wouldn't normally do this when you do arithmetic. At least,
not the arithmetic I was taught in school! The point is only a limited subset
of operations out of a limitless number of operations are valid for a particular
type of data. Also, data can be combined or used in such a way that makes
it an entirely new type of data altogether. For example, a series of letters
makes a string. A string in the form of plain language and has some
meaning attached to it is a word. A unique series of words makes up a vocabulary
or dictionary. A pair of numbers could be used as a coordinate. Two coordinates
describes a square, box or window. These data types that I've just
described could each have unique operations that are valid only for them.
The old style of dealing with different types of data was just to pass them
off to sub-procedures and have them check whether or not they were passed
valid data to work on. The sub-procedures would accept arguments that
are passed to it from the main program or from other sub-procedures. However,
this places the responsibility on the programmer to match every piece of data
correctly with every procedure that is used in the program. This style of
programming is called procedural or structural programming. In this style
the procedures or operations to be performed on data is separate from the
data itself. The idea is that in a program, data is passed to a procedure or
a series of procedures which operates on the piece of data in order to manipulate
it. Some people thought that separating the data from the procedures that is
applied on them and having to explicitly "pass" each piece of data to the corresponding
procedure in order to manipulate the data was too much mucking around and too
messy.
This brings us to the concept of an Abstract Data Type or ADT for short. The
ADT demonstrates the technique of abstraction for simplifying the data
elements and their relationships within a program. The ADT builds a conceptual
model for a particular type of data by grouping the data elements that composes
the data type with the specific operations which are required and valid for it.
Instead of having data operations and data elements separated within a program and
matched data-to-procedure. the ADT model requires that each piece of data and
their corresponding operations be grouped together. Also with an ADT the
specification of the ADT is separate from the declarations which implements
it. This is because an ADT is an abstract model of the data type. With
an ADT you can specify what operations a particular type of data should support
while leaving the actual the implementation of the data type independent from the
its specifications. Why would you want to do that? Well, because its one of the
most powerful techniques available to the software engineer when designing a
program. This is because during the construction of the program once you have
the behaviour of each of the data types specified, performing an operation
on a piece of data is simply a matter of calling the appropriate member
function that is part of the ADT. Since the details of the implementation
for the particular data type is hidden within the ADT class this is one
less component of the program the programmer needs to worry about. Another
advantage of this is since, the implementation for accessing and manipulating the
data is hidden with the only interface "outside" of the ADT done through
member functions (also called methods), the ADT becomes a
self-contained module.
This self-contained property of an ADT offers a number of important
advantages:
- Code reuse. Since ADTs are self-contained modules they can be easily
reused in other parts of the program or even other projects with little or
no modifications.
- Interchangeable modules. Providing that the public interface to the
ADT hasn't change we can experiment among a variety of different implementation
of the ADTs in our program. We can do this because the implementation of the
ADT is hidden internally and has no influence on the actual interface. Essentially
we can have interchangeable parts of our programs that we simply "plug in".
- Hierarchy of layers or levels. Since the only "visible" part of the ADT is
the interface the ADT module becomes a black box. By this I mean that other
programmers that use the ADT module don't care and don't need to care about how
the ADT works, but only how to use it. Furthermore, by using this property programs
can be layered, so that hardware and system details can be made independent
of the actual logic of an algorithm or from the actual "big picture" design of
a program.
An abstract data type is a formal description of data elements and relationships
as envisioned by the software engineer; it is thus a conceptual model. Ultimately
this model must be implemented in an appropriate programming language.
The specification of an abstract data type involves three factors:
- A description of the elements that compose the data type.
- A description of the relationships between the individual components in
the data type.
- A description of the operations we wish to perform on the components of
the data type.
A simple example of abstraction would be an alarm clock. The alarm clock
has a display showing the time. And some buttons for setting the current time
and the activation time for the alarm. Of course there is more to the alarm clock
than this. If the alarm clock is one of the popular electronic versions that are
used today then there is also the digital circuitry that is needed to control
the alarm clock. The digital circuitry itself must be put together in a certain
way that allows it to function as an alarm device. But, as a user of the alarm
clock you don't think about nor do you need to think about these internal details.
This is because the alarm clock acts as an ADT. The user interface which would
be the buttons on the alarm clock is analogous to the member functions for the
ADT. The internal circuitry of the alarm clock is analogous to the programming
logic and algorithms implemented within the member functions of the ADT. Similar
to the ADT in which all "outside" interactions to the ADT is done through its
user interface by calling its member functions, all interactions on
the alarm clock is done through its user interface by pressing the buttons on it.
Abstraction create black boxes by hiding the internal low level details
to create a higher level of interaction between the user and the device. The
device itself could either be a virtual device as in a piece of
program logic or a physical device as in an alarm clock it doesn't
matter the concept is the same.
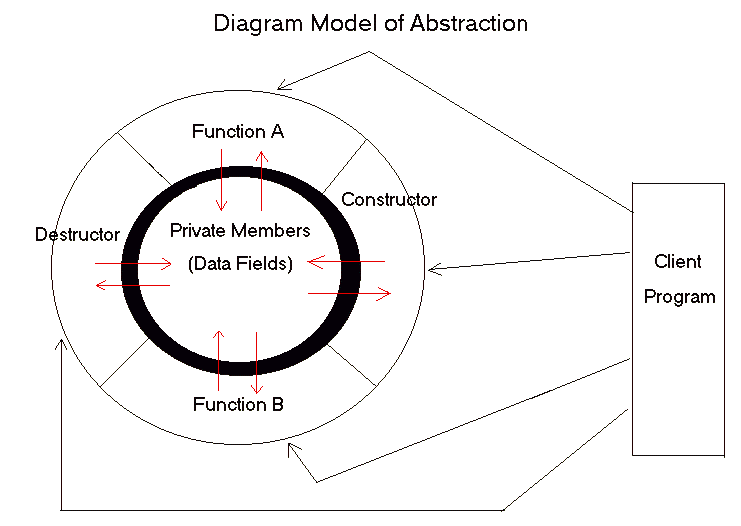
Here's a diagram which illustrates how abstraction works in C++. The thick
line of the inner circle containing the data members of the class,
indicates that they are not visible to the main client program, but only
visible to the member functions of the class. Function A, Function B, Destructor
and Constructor are all member functions of this particular class. The only way
the client program can manipulate the data of the class is to call these
member functions (black arrows). The member functions in turn sets up the
two-way communication (red arrows) between the actual data of the class and
the client program through a piece of programming code design specifically
for the task the member function is to accomplish. All the messy, uninteresting,
low-level details are hidden within the code of the member functions. All that
the client needs to know is which member function to call for accomplishing a
particular task.
Physical Models, Virtual Models and Virtual Machines
Because abstraction can be applied to both physical and virtual devices and
since an ADT is a conceptual model developed through abstraction, this leads
us to another important feature of the ADT. An ADT can be used to model physical
devices and systems. By doing this, physical devices and virtual devices can
become interchangeable (at least within a computer program). Physical devices
can model virtual devices and vice versa. This is the basic idea behind virtual
machines. This includes the popular Java Virtual Machine which executes the
bytecodes of a Java program in different hardware and system environments
provided that the virtual machine is implemented on its native platform.
Abstract Data Types (ADTs) are implemented in C++ through the class
language feature.
E-mail: cybernadian1@yahoo.ca
 cybernadian1@yahoo.ca
cybernadian1@yahoo.ca